增加运动因素
使用上面介绍的方法,像JPEG这样的静态图像压缩算法可以在压缩率为10:1的条件下获得很好的图像质量。最先进的静态图像编码器在压缩率高达30:1下也能获得很好的图像质量。视频压缩算法采用运动估计和补偿可以利用连续视频帧之间的相似性。这样可以使视频压缩算法在压缩率达200:1的情况下获得很好的视频质量。
在某些视频场景下,例如新闻节目中运动图像很少。在这种情况下,每个视频帧中的8x8像素的块大部分与前一帧是相同的,或者接近相同。压缩算法通过运算两个帧之间的差异性可以利用这一事实,利用上面介绍的静态图像压缩方法来对这种差异性进行编码。对于大部分图像块来说,这种差异性很小,与单独对每个帧进行编码相比,这种方法需要的编码数据位非常少。然而,如果摄像机是进行摇摄的或者场景中某个大的物体在移动,那么每个块将不再与前一帧中对应块相同。相反,与前一帧中8x8像素区域相似的块位置发生了偏移,产生了与运动方向对应的一个距离。值得注意的是,每个视频帧通常由两个色度层和一个亮度层组成,如上面所述。很显然,每个层的运动情况是相同的。尽管亮度和色度层的分辨率不同,为利用这种事实,以宏块而不是以三个层中单独的8x8像素块进行运动研究。
运动估计和补偿
运动估计是尝试发现在前一编码帧(称为“基准帧”)中的一个与当前帧中每个宏块紧密匹配的区域。对于每一个宏块来说,运动估计产生一个“运动矢量”。运动矢量是由当前帧中宏块相对于所选择的16x16像素区域的基准帧中位置的水平和垂直偏移组成。视频编码器通常使用VLC来对视频码流中的运动矢量进行编码。所选择的16x16像素区域被用于当前宏模块中像素的预测,使用上面介绍的静态图像压缩方法来进行宏块之间的差异以及所选择区域(预测误差)的运算和编码。绝大多数的视频压缩标准允许在编码器不能发现宏块的足够好的匹配时,忽略这种预测。这时,对宏块本身进行编码,而不是对预测误差进行编码。
值得注意的是,基准帧并不总是连续视频帧中的前一个显示帧。视频压缩算法通常对帧的编码顺序与他们显示的顺序是不相同。编码器可能向前跳过几个帧,对未来的帧进行编码,然后跳回来,对显示序列中的下一个帧编码。之所以这样做,是因为可以利用编码的未来帧作为基准帧向后及时地实现运动估计。视频压缩算法还可以使用两个基准帧—一个是前面已显示的帧,一个是前面已编码的未来帧。这样允许编码器从任意一个基准帧中选择一个16X16像素的区域,或者在前面显示帧的16X16像素区域和未来帧的16X16像素区域之间通过插值方法预测一个宏块。
依赖前一个编码帧来对每一个新帧解码进行修正的一个缺点是,一个帧的传递错误会使每个紧随而来的帧不能重建。为缓解这个问题,视频压缩标准偶尔只使用静态图像编码方法对一个视频帧进行编码,而不需依赖于前一个编码帧。这些帧就成为“内帧”(或I frame,即I帧)。如果压缩码流中的一个帧因为错误而被破坏,视频解码器必须等到下一个I帧,这种方法就不需要基准帧来进行视频重构。
仅仅使用前一个显示的基准帧来编码的帧被称为“P帧”,同时使用前一个显示帧和未来帧作为基准帧进行编码的帧称为“B帧”。在通常的场景中,编解码器编码一个I帧,然后向前跳过几个帧,用编码I帧作为基准帧对一个未来P帧进行编码,然后跳回到I帧之后的下一个帧。编码的I帧和P帧之间的帧被编码为B帧。之后,编码器会再次跳过几个帧,使用第一个P帧作为基准帧编码另外一个P帧,然后再次跳回,用B帧填充显示序列中的空隙。这个过程不断继续,每12到15个P帧和B帧内插入一个新的I帧。例如,图1种给出了一个典型的视频帧序列。
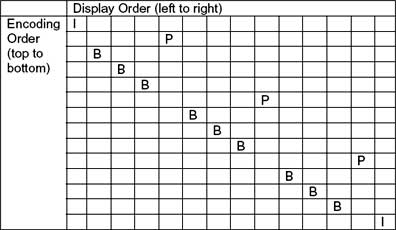
图1:典型的I、P和B帧序列。
视频压缩标准某些时候限制运动矢量的水平和垂直分量,这样在运动估计时每个宏块和所选择的16x16像素区域之间最大可能的距离会远小于帧的宽度或高度。这种限制轻微地减少了对运动矢量进行编码所需要的数据位数,也减少了执行运动估计所需要的运算量。包含在允许的运动矢量中的所有可能的16x16像素区域的基准帧部分被称为“搜寻区域”。
此外,先进的视频压缩标准允许运动矢量具有非整数的值。即,编码器可能估计针对某个指定宏块当前帧与基准帧之间的运动距离不是整数个像素。运动矢量的分辨率为半个或四分之一个像素很常见。因此,为预测当前宏块中的像素,必须对基准帧中的对应区域进行插值处理来估算出在非整数像素位置的像素值。按上面介绍的方法对预测与实际像素值之间的差值进行计算并编码。
运动估计是图像压缩应用中运算量非常大的任务,需要视频编码器80%的处理能力。最简单彻底的运动估计方法是在搜寻区域中评估每一个可能的16x16像素区域,选择最匹配的。通常,利用“绝对差异值之和”(SAD)或“平方差异值之和”(SSD)运算来确定一个16x16像素区域与一个宏块到底有多匹配。通常只对亮度层进行SAD和SSD运算,但是也可以包括色度层。例如,一个48x24像素的相对较小搜寻区域可能包括分辨率为?像素的1024个16x16区域。仅对这样一个区域的亮度层进行SAD运算需要做256次减法、256次绝对值运算以及255次加法运算。因此,还不包括非整数运动矢量所要求的插值处理,要进行最佳的匹配,这样的搜寻区域进行彻底的扫描所需要的运算单个宏块需要785,408次算术运算,这相当于在CIF分辨率(352x288像素),帧率为每秒15帧下,每秒4.6亿次算术运算。
由于这种高运算量,运动估计的实际实现并不适用彻底搜寻。相反,运动估计算法使用各种方法来选择有限数量的备选运动矢量(大多数情况下大约10到100个矢量),只对与这些备选矢量对应的16x16像素区域进行评估。一种方法是在几个阶段来选择备选运动矢量。例如,可能选择5个初始备选矢量,并进行评估。结果用来清除搜寻区域中不可能的部分,对搜寻区域中最有可能的部分进行处理。选择5个新的矢量,并重复这种处理。通过几次这样的过程,就可以得到最佳的运动矢量。
在视频序列中的当前帧和前一帧中针对周边宏块所选择的运动矢量的另一种分析方法是试图预测当前宏块中的运动。根据这种分析来选择一些备选的运动矢量,并只对这些矢量进行评估。
通过选择一个较少的被选矢量而不是对搜寻区域的彻底扫描,运动估计的运算需求可以大大地减少,某些时候超过两个数量级。值得注意的是,在图像质量/压缩率和运算量之间具有一种折衷关系:使用更多的运动矢量允许编码器在基准帧内找到一个16x16像素的区域,这些区域能更好地匹配每一个宏块,这样减少预测误差。因此,增加被选矢量允许预测误差以更少的数据位或者更高的精度进行编码,而代价就是执行更多地SAD(或者)SSD运算。
除了上面描述的两种方法外,还有很多其他选择适当备选运动矢量的方法,包括各种的专有解决方案。大多数视频压缩标准仅仅规定了压缩视频码流的格式以及解码步骤,而对编码过程无定义,因此编码器可以采用各种方法来进行运动估计。
运动估计方法是那些符合相同标准的视频编码器实现之间的最大差异。运动估计方法的选择大大地影响了运算要求和视频质量,因此市场上提供的编码器内的运动估计方法细节常常是严格保守的商业秘密。
很多针对多媒体应用的处理器都提供了加速SAD运算的专门指令,或者专用的SAD协处理器来从CPU转移这种需要大量运算的任务。
值得注意的是,为了执行这种运动估计,除了当前帧以外,编码器必须在存储器中保留一个或两个基准帧。所需要的帧缓存通常都比片上可提供的存储器大很多,在很多应用中都需要额外的存储器芯片。将基准帧存储在片外存储器中导致要求编码器非常高的外部存储器带宽,尽管大的片上缓存有助于大大减少所要求的带宽。
某些视频压缩标准允许每个宏块被分割成两个或四个部分,每个部分有一个独立的运动矢量。与一个运动矢量相比,这种选择需要更多的数据位来对两个或四个部分进行编码。然而,如果增加的运动矢量能更好地预测宏块像素,则对每个预测进行编码所需要的数据位更少,这又是很有益的。